ປະຫວັດພາສາລາວ
ຊຸດຕົວອັກສອນລາວ
ໜັງສືລາວ ມີຕົ້ນກຳເນິດມາຈາກ ພາສາ ບາລີ ແລະ ສັນສະກິດ, ເຊີ່ງຕົວອັກສອນທີ່ນຳໃຊ້ໃນການສື່ສານ ແມ່ນມີເຄົ້າມາຈາກ ພາສາສັນສະກິດ, ສ່ວນຕົວອັກສອນທີ່ມີເຄົ້າມາຈາກພາສາບາລີ ແມ່ນນຳໃຊ້ໃນ ພາສາທັມ. ຕົວອັກສອນລາວ ປະກອບມີ 56 ຕົວໜັງສື ແລະ ເຄື່ອງໝາຍ ເຊີ່ງປະກອບມີ: 33 ພະຍັນຊະນະ, 28 ສະຫຼະ, 4 ວັນນະຍຸດ, 3 ເຄື່ອງໝາຍພິເສດ ແລະ 10 ຕົວເລກລາວ.
1. ພະຍັນຊະນະ:
ໃນຈຳນວນ 33 ພະຍັນຊະນະຂອງພາສາລາວ ລວມມີ 27 ພະຍັນຊະນະດ່ຽວ ແລະ 6 ພະຍັນຊະນະປະສົມ.
1.1 ພະຍັນຊະນະດ່ຽວ ແມ່ນມີຄື:
ກ(1); ຂ(2); ຄ(3); ງ(4); ຈ(5); ສ(6); ຊ(7); ຍ(8); ດ(9); ຕ(10); ຖ(11); ທ(12); ນ(13); ບ(14); ປ(15); ຜ(16); ຝ(17); ພ(18); ຟ(19); ມ(20); ຢ(21); ຣ(22); ລ(23); ວ(24); ຫ(25); ອ(26); ຮ(27);
1.2 ພະຍັນຊະນະປະສົມ ແມ່ນມີຄື:
ຫ(24) + ງ(4) = ຫງ(28); ຫ(24) + ຍ(8) = ຫຍ(29); ຫ(24) + ນ(13) = ໜ(30)
ຫ(24) + ມ(20) = ໝ(31); ຫ(24) + ລ(22) = ຫລ or ຫຼ (32); ຫ(24) + ວ(23) = ຫວ(33)
2. ສະຫຼະ ແມ່ນມີຄື: ◌ະ(1); ◌າ(2); ິ(3); ີ(4); ຶ(5); ື(6); ຸ(7); ູ(8); ເ◌ະ(9); ເ◌(10); ແ◌ະ(11); ແ◌(12); ໂ◌ະ(13); ໂ◌(14); ເ◌າະ(15); ໍ(16); ເິ(17); ເີ(18); ເັຽ(19); ເ◌ຽ(20); ົວະ(21); ົວ(22); ເຶອ(23); ເືອ(24); ໄ◌(25); ໃ◌(26); ຳ (27); ເົາ(28).
3. ວັນນະຢຸດ ແມ່ນມີຄື: x່ x້ x໊ x໋
4. ເຄື່ອງໝາຍພິເສດ: "ໆ"; "ຯ"; "໌"
5. ຕົວເລກລາວ: ໐; ໑; ໒; ໓; ໔; ໕; ໖; ໗; ໘; ໙
ຕົວໜັງສື (Character) ແມ່ນອົງປະກອບນ້ອຍທີ່ສຸດ ຂອງການຂຽນພາສາ ທີ່ມີຄຸ່ນຄ່າໃນການໃຫ້ຄວາມໝາຍຂອງຄຳ, ເຊິ່ງອ້າງອິງເຖີງ ຄວາມໝາຍ ອາການ ແລະ/ຫຼື ຮູບຮ່າງ, ເພາະຢູ່ໃນຕາຕະລາງຕົວໜັງສືນັ້ນ ມັນມີຄວາມຈຳເປັນ ທີ່ຈະຕ້ອງໃຫ້ຜູ້ອ່ານສາມາດເຂົ້າໃຈ ຄວາມໝາຍຂອງແຕ່ລະຕົວໜັງສືໄດ້.
ຂໍ້ມູນຂ່າວສານ ທີ່ບັນຈຸໃນຄອມພິວເຕີ ແມ່ນເປັນລັກສະນະຕົວເລກຖານສອງ (ຄື 0 ກັບ 1), ໂດຍຄອມພິວເຕີ "map" ຈະໃຫ້ແຕ່ລະຄ່າຕົວເລກ ແທນຕົວໜັງສືນັ້ນໆ, ເຊີ່ງໂດຍທົ່ວໄປແລ້ວເອີ້ນວ່າ ຕາຕະລາງຕົວໜັງສື ບັນທຶກໃນລະບົບຄອມພິວເຕີ (Character Set or the Code Page). The Character set ແມ່ນການບັນທຶກເປັນລໍາດັບ ຂອງຕົວໜັງສື (ພະຍັນຊະນະ/ຕົວເລກ ແລະ ເຄື່ອງໝາຍ) ທີ່ນຳໃຊ້ເພື່ອທຽບຕົວໜັງສືໃນແປ້ນພີມ, ເພື່ອສະແດງຕົວໜັງສືໃນຈໍພາບ, ແລະ ເພື່ອແລກປ່ຽນຕົວໜັງສື ໃນຮູບແບບດີຈີຕັນ (ຕົວເລກ). ຖ້າປັດສະຈາກ Character Set ແລ້ວ ແມ່ນບໍ່ສາມາດ ທີ່ຈະ ປ້ອນເຂົ້າ, ພີມອອກ, ບັນທຶກ ແລະ ຂົນສົ່ງ ຂໍ້ມູນຂ່າວສານເລົ່ານັ້ນ ໃນລະບົບຄອມພິວເຕີ ແລະ ເຄື່ອງເອເລັກໂທຼນິກ ອື່ນໆ ໄດ້ຢ່າງເດັດຂາດ.
ໃນປີ 1993 ອົງການມາດຕະຖານສາກົນ ໄດ້ສ້າງ ມາດຕະຖານສາກົນກ່ຽວກັບ ຕາຕະລາງຕົວໜັງສືທີ່ມີຫລາຍພາສາ ທີ່ພວກເຮົາຮູ້ໃນນາມ ISO 10646 ແລະ ກໍ່ໄດ້ມີການໂອນປ່ຽນມາເປັນ Unicode. ບໍ່ຮູ້ວ່າ ມັນເປັນການໂຊກດີ ຫຼື ໂຊກຮ້າຍ ສຳລັບ ພາສາລາວ ຂອງພວກເຮົາ ທີ່ທາງອົງການສາກົນ ໄດ້ບັນຈຸພາສາລາວເຂົ້າໃນລະບົບຕາຕະລາງດັ່ງກ່າວ ຕັ້ງແຕ່ລິເລີ້ມສ້າງຕັ້ງຕາຕະລາງ, ໂດຍບໍ່ຮູ້ວ່າແມ່ນໃຜເປັນຜູ້ສະເໜີ.
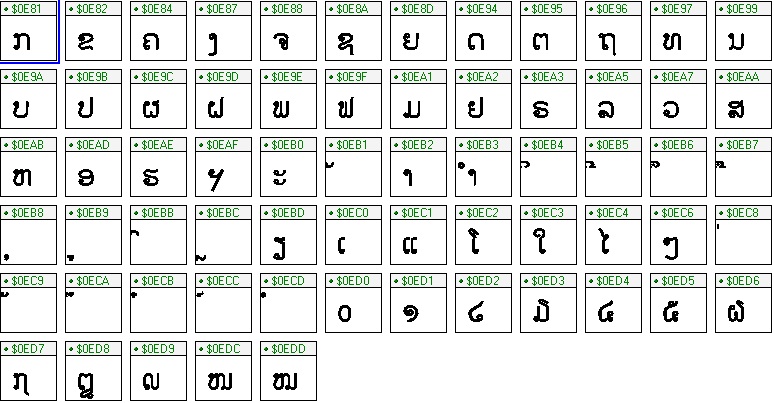
ຢູ່ໃນຕາຕະລາງນີ້ປະກອບມີ 65 ເຄື່ອງໝາຍ ຂອງຕົວໜັງສືລາວ ເຊີ່ງທັງໝົດກໍ່ລ້ວນແຕ່ບັນຈຸຢູ່ໃນຫລັກໄວຍະກອນລາວ ເຊີ່ງໄດ້ແກ່: 27 ພະຍັນຊະນະດ່ຽວ, 03 ພະຍັນຊະນະປະສົມທີ່ເປັນຮູບດ່ຽວ, 18 ສະຫຼະດ່ຽວ, 04 ວັນນະຢຸດ, 03 ເຄື່ອງໝາຍພິເສດ ແລະ 10 ຕົວເລກລາວ.
ຢູ່ໃນຕາຕະລາງ Unicode, ຕົວໜັງສືລາວແມ່ນໄດ້ຖືກບັນຈຸໃສ່ ໃນຫ້ອງທີ່ 0x0E80 ຫາ 0x0EFF, ເຊີ່ງບໍ່ມີພາສາອື່ນໃດທີ່ຈະມາບັນຈຸໃສ່ບັນດາຫ້ອງທີ່ຈັດຫາເລົ່ານີ້. ສ່ວນເຄື່ອງໝາຍ ແລະ ຕົວເລກອາລັບ ທີ່ນຳໃຊ້ໃນພາສາລາວນັ້ນ ແມ່ນຖຶກບັນຈຸໃນຫ້ອງ 32 ຫາ 255. ແຕ່ຜູ້ທີ່ນຳສະເໜີຕາຕະລາງຕົວໜັງສືລາວນັ້ນ ໄດ້ມີການຈັດລຽງລຳດັບຕົວອັກສອນລາວ ບົນພື້ນຖານທຽບສຽງກັບຕົວອັກສອນໄທ, ແຕ່ເນື່ອງຈາກວ່າ ພາສາໄທ ມີຈຳນວນຕົວອັກສອນ ຫລາຍກ່ວາພາສາລາວ, ຖ້າກໍລະນີ ຕົວອັກສອນລາວຕົວໃດ ທີ່ບໍ່ມີສຽງຄືກັບຕົວອັກສອນໄທແລ້ວ, ຜູ້ສະເໜີກໍ່ປະຕາຕະລາງເປັນຫ້ອງວ່າງເປົ່າ. ເຖີງແມ່ນວ່າພວກເຮົາບໍ່ສາມາດ ເຮັດການຈັດລຽງພາສາລາວ ໂດຍອີງຕາມໂຄງສ້າງ ຂອງຕາຕະລາງພາສາລາວໃນ Unicode ໄດ້, ແຕ່ຕາຕະລາງດັ່ງກ່າວ ກໍ່ໃຫ້ພວກເຮົາສາມາດຂຽນ ພະຍາງ ແລະ ຄຳສັບໃນພາສາລາວ ໄດ້ທັງໝົດ.
ຮູບແບບຕົວໜັງສື
ໂຕພີມໜັງສື (Font) ແມ່ນການສະສົມ ບັນດາຮູບຕົວໜັງສື ເພື່ອພັນລະນາໃຫ້ເຫັນ ຂໍ້ມູນຂອງຕົວໜັງສື. Font ປະກອບດ້ວຍບັນດາອົງປະກອບຂອງຕົວໜັງສື ເຊັ່ນ: ຂະໜາດ, ຮູບແບບ,, ຄວາມກ້ວາງ, ຄວາມສູງ, ເຊີ່ງເມື່ອພວກເຮົາໃຫ້ຄ່າທາງຕົວເລກມັນແລ້ວ ຈະສາມາດ ໃຫ້ກຳເນິດ ຮູບພາບຂອງຕົວໜັງສື.
Font ປະກອບມີສາມອົງປະກອບຄື: ລະຫັດຂອງໂຕພີມໜັງສື, ຖານຂໍ້ມູນຮູບພາບຂອງຕົວໜັງສື ແລະ ຕາຕະລາງຕົວໜັງສື
ລະຫັດຂອງໂຕພີມໜັງສື (Coded Font) : Coded font ແມ່ນການແປ ສີ່ງທີ່ທ່ານຕ້ອງການຂຽນ (ຕົວຢ່າງ: ຂໍ້ຄວາມ ທີ່ທ່ານ ພີມເຂົ້າໄປໃນຄອມພີມເຕີ)ໃຫ້ກາຍເປັນ ໂຕໜັງສື ສຳລັບພີມ. ລະຫັດຂອງໂຕ ພີມໜັງສື ທີ່ເຮັດວຽກພົວພັນກັບ ຕາຕະລາງຕົວໜັງສື ແລະ ຖານຂໍ້ມູນຮູບພາບຂອງຕົວໜັງສື ປະກອບດ້ວຍສອງພາກສ່ວນຄື: ພາກສ່ວນທີ່ ພົວພັນ ກັບ ຖານຂໍ້ມູນຮູບພາບຂອງຕົວໜັງສື ແລະ ພາກສ່ວນທີ່ພົວພັນ ກັບຕາຕະລາງຕົວໜັງສື
ຖານຂໍ້ມູນຮູບພາບຕົວໜັງສື (Font Character Set): Font character ປະກອບດ້ວຍ ບັນດາຕົວໜັງສື ທີ່ມີນາມສະກຸນໜຶ່ງດຽວກັນ, ຮູບຮ່າງໜ້າຕາຂອງຕົວພີມ ແລະ ຂະໜາດຂອງຕົວພີມ. ນອກຈາກນັ້ນ ຖານຂໍ້ມູນຮູບພາບຕົວໜັງສື ຍັງໄດ້ລະບຸເຖີງ ຄຸນສົມບັນ ຂອງຕົວໜັງສື ແລະ ຄຸນສົມບັດຂອງການພີມ.
ຕາຕະລາງຕົວໜັງສື (Code Page)
ຕາຕະລາງຕົວໜັງສື ແມ່ນຈະເຮັດການ ທຽບຄ່າ ຂອງແຕ່ລະຕົວໜັງສື ໃນຂໍ້ຄວາມ ກັບ ຖານຂໍ້ມູນຮູບພາບຕົວໜັງສື. ຖ້າຫາກ ທ່ານ ປ້ອນຂໍ້ຄວາມເຂົ້າໃນເຄື່ອງຄອມພິວເຕີ, ແຕ່ລະແປ້ນພີມ ຈະເຮັດການ ແປຕົວໜັງສືທີ່ພີມ ໄປເປັນລະຫັດຕົວເລກ. ເມື່ອເວລາ ຂໍ້ຄວາມຈະພີມອອກ, ແຕ່ລະ ລະຫັດຕົວເລກ ຈະທຽບຄ່າກັບ ລະຫັດຂອງຕົວໜັງສື ໃນຕາຕະລາງໂຕໜັງສື, ເຊີ່ງຖ້າຫາກ ລະຫັດໂຕໃດຫາກມີ ຄ່າ ຄືກັນ, ໂປຼແກຼມ ກໍ່ຈະພີມຮູບພາບຂອງຕົວໜັງສືນັ້ນອອກມາ. ຮູບຂ້າງລຸ່ມ ຈະສະແດງໃຫ້ເຫັນວ່າ ຕາຕະລາງຕົວໜັງສື ເຮັດການ ທຽບຄ່າ ກັບຖານຂໍ້ມູນຮູບພາບຕົວໜັງສື.
ຄວາມສູງຂອງຕົວໜັງສື ທີ່ຢູ່ໃນລະດັບຕ່າງກັນນັ້ນ ແມ່ນ ບໍ່ເທົ່າກັນ, ແຕ່ເມື່ອສັງເກດເບີ່ງແລ້ວເຫັນວ່າ ຕົວໜັງສືໃນລະດັບສາມ ຈະສູງຍາວກ່ວາໝູ່, ເຊີ່ງ ຕົວໜັງສື ໃນລະດັບ ສອງ ແລະ ສີ່ ແມ່ນ ຈະເທົ່າເຄິ່ງໜຶ່ງ ຂອງຕົວໜັງສືໃນລະດັບສາມ, ສ່ວນຄວາມສູງຂອງຕົວໜັງສື ໃນລະດັບໜຶ່ງ ຈະເທົ່າເຄິ່ງໜຶ່ງ ຂອງ ຕົວໜັງສື ໃນລະດັບ ສອງ.
ຄຸນລັກສະນະ ຂອງ ຮູບຕົວໜັງສືລາວ ສາມາດ ແບ່ງອອກເປັນ 6 ໝວດຄື:
1. ໝວດຢູ່ເທີງສຸດ (Above1): ໄດ້ແກ່ ວັນນະຢຸດ ແລະ ໄມ້ກະລັນ: ່, ້, ໊, ໋, ໌.
2. ໝວດຢູ່ເທີງທີ່ສອງ: ໄດ້ແກ່ສະຫຼະທັງເທິງຄື: ົ, ັ, ໍ, ິ, ີ, ຶ, ື.
3. ໝວດທີ່ຢູ່ເສັ້ນຫລັກ (Base line): ໄດ້ແກ່ ພະຍັນຊະນະ, ສະຫຼະທາງໜ້າ ແລະ ທາງຫຼັງ ແລະ ເຄື່ອງໝາຍພິເສດ, ເຊີ່ງ ສາມາດແບ່ງອອກເປັນສາມຈຸຄື:
_ ພະຍັນຊະນະທີ່ມີຄວາມສູງທຳມະດາ: ກ, ຂ, ຄ, ຈ, ສ, ຍ, ດ, ຕ, ທ, ນ, ບ, ຜ, ພ, ມ, ຣ, ລ, ວ, ຫ, ອ, ຮ
_ ພະຍັນຊະນະທີ່ສູງກາຍມາລະດັບສອງ: ປ, ຝ, ຟ, ຢ, ໄ, ໃ, ໂ ເຊີ່ງຕ້ອງໄດ້ Kerning
_ ພະຍັນຊະນະ ທີ່ຍາວລົງມາ ລະດັບສີ່: ຊ, ຖ, ງ, ຽ. ເຊີ່ງຕ້ອງໄດ້ Mark to base
4. ໝວດທີ່ຢູ່ຕໍ່າທີ່ 1: ໄດ້ແກ່ພະຍັນຊະນະ " ຼ"
5. ໝວດທີ່ຢູ່ຕ່ຳທີ່ສອງ 2: ໄດ້ແກ່ ສະຫຼະຢູ່ທາງລຸ່ມ: "ຸ", 'ູ'
6. ໝວດທີ່ຕ້ອງການ ກຳນົດຄຸນລັກສະນະພິເສດ: ໄດ້ແກ່ສະຫຼະ "ໍາ"
ຕາຕະລາງຕົວໜັງສືລາວ ໃນລະບົບ ຢູນີໂກດ